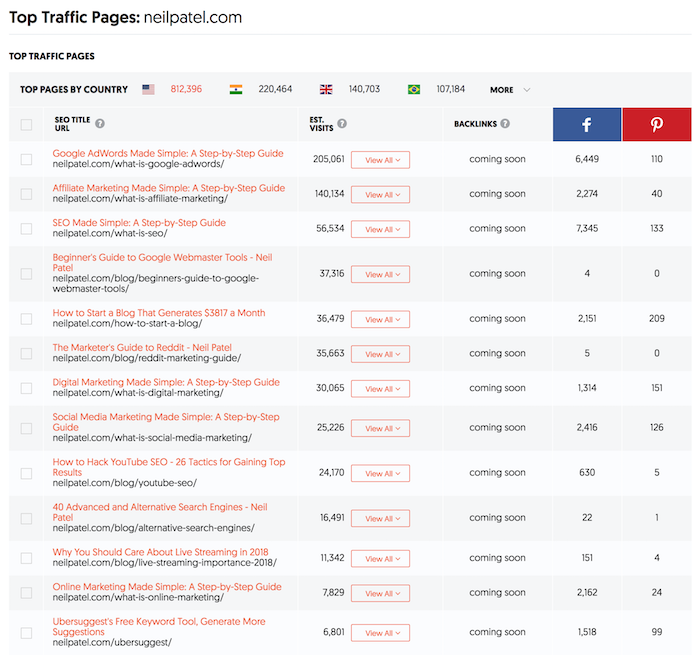
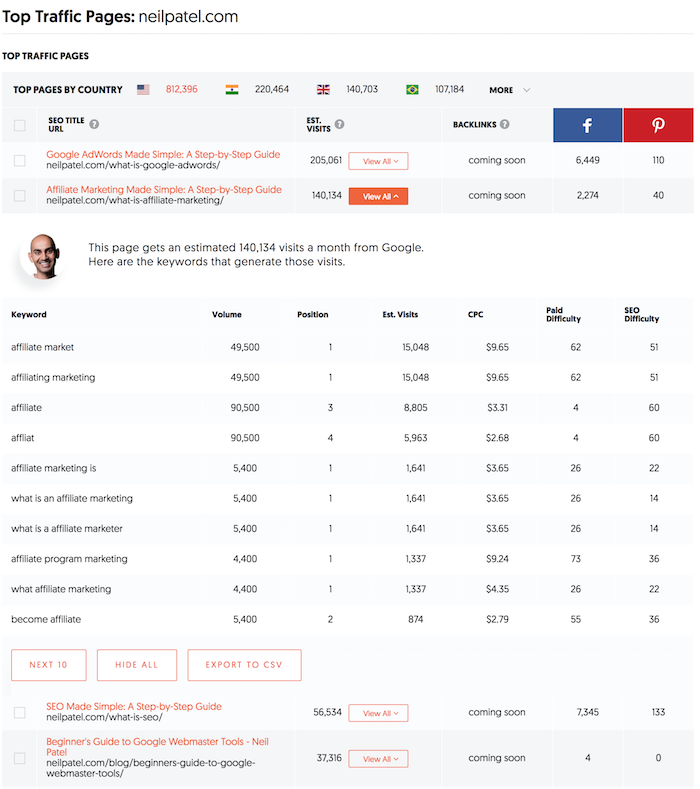
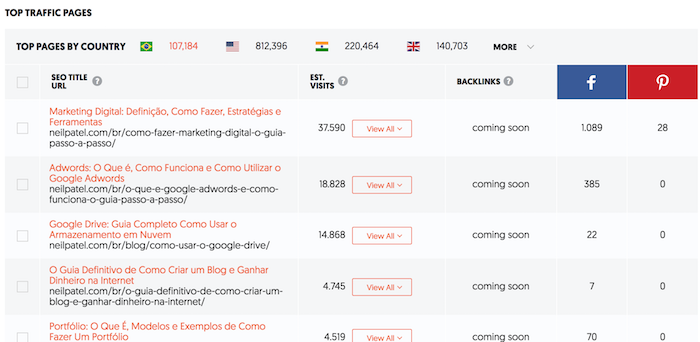
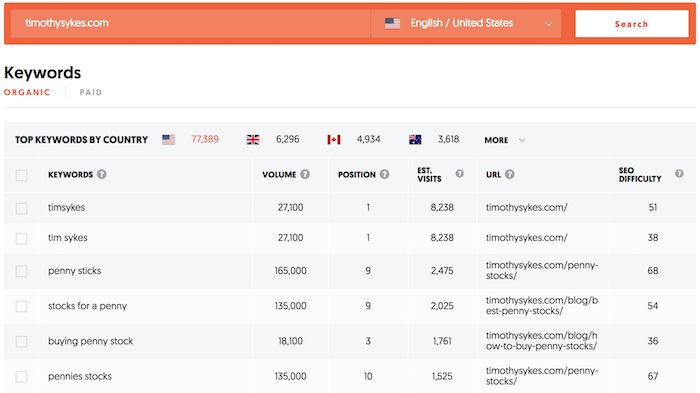
Ashley Whillans, professor at Harvard Business School, researches time-money trade-offs. She argues more people would be happier if they spent more of their hard-earned money to buy themselves out of negative experiences. Her research shows that paying to outsource housework or to enjoy a shorter commute can have an outsized impact on happiness and relationships. Whillans is the author of the HBR article “Time for Happiness.”
Download this podcast
TRANSCRIPT
CURT NICKISCH: Welcome to the HBR IdeaCast from Harvard Business Review. I’m Curt Nickisch.
I keep thinking about something that a guest said recently on the show.
TERESA AMABILE: We have been living for several decades as kind of a tenant of a life structure that our organization has created for us. We know where we’re going to be at 9am Monday through Friday. Our weekends are also structured around that, because you know maybe one day or part of a day is the day we do all the chores that we didn’t have a chance for.
CURT NICKISCH: That was Teresa Amabile on episode 665. She said it in reference to her research on retirement. But what really struck me is this idea that your job even dictates how you spend your time off.
And that’s why I’m excited for today’s episode. Our guest today believes people would be happier if they spent more of the money they earn at work to get back more of their time when they’re not working.
Ashley Whillans researches the trade-offs we make between time and money – and says we often get those wrong. She says we should spend more money not just on things we like, but to get us out of things we don’t enjoy, like yard work, cooking, and commuting.
Ashley Whillans is an assistant professor at Harvard Business School. She’s also the author of the HBR article “Time for Happiness.” Ashley, thanks for coming on the show.
ASHLEY WHILLANS: Thanks so much for having me.
CURT NICKISCH: Your research concluded that the happiest people use their money to buy time. And there’s that phrase, you know, money can’t buy you happiness, but you’re basically saying that if more people used money to buy time that they could use that time to be more happy.
ASHLEY WHILLANS: Yeah. So we really like to flip this Benjamin Franklin’s adage on its head and say, “Well, if time is money, maybe also we can think that money can buy a happier time.” My research really focuses on using money to buy ourselves out of negative experiences. So subtracting negative minutes from our day, subtracting time that we spend stuck in traffic, subtracting extra work hours where we’re just spinning our wheels and really we should go home, subtracting housecleaning.
But really any way that we spend money in a way that might save us time – such as also buying ourselves into positive experiences – has reliable and positive effects on the happiness that we get from our days, our weeks, our months and our lives.
CURT NICKISCH: Even though people feel like the world is busier than ever, you know, you point out in your research that the average American, for instance, has more time for leisure than they did 40 years ago. And so it sounds like you’re saying that now that people have more time, they just spend it earning more money or taking jobs that make them busier rather than using the time.
ASHLEY WHILLANS: Yeah, I think it’s really interesting that, you know, work hours have gone down, but people are feeling more stressed. And I think it’s exactly this – we think that busyness is a status symbol. We focus our attention on getting ahead, especially in North American culture. So I think there’s this element, one, of the fact that even though we have more free time, we might fill it more with work or commuting really far away because we want to have this really nice house that we don’t get to spend any of our time in. We don’t get to enjoy because we’re always commuting to work really far.
And a ubiquitous connection to the internet also means that we experience what some researchers have called “time confetti.” So not only maybe are we trying to fill our time with more work and being more productive, but also our time is more fragmented. We’re more distracted, and that also contributes to these higher feelings of time stress.
But also, time is very hard to track and so if we have windfalls of time, we often fritter them away. So what’s interesting is that in one of my collaborators’ and mine studies, we find that buying time or spending money on time-saving services predicts greater happiness and reduces stress, not because of the objective amount of time that we saved.
Just the simple act of thinking about giving up money to have more free time seems to make people plan their time a little bit better. If I’m going to incur this cost to have this free time, then I’m going make sure I really enjoy the free time that I have.
CURT NICKISCH: What do you make of the argument though, that the future is uncertain and financial security or your financial future is often uncertain too, and so I guess some of the way we’ve been trained to think about time versus money is that, like, if you have time now and can make money, you need to save so that in the future when you’re not working, you have money to spend?
ASHLEY WHILLANS: Yeah, and I mean people who feel uncertain about their financial future are more likely to value money and they get more satisfaction out of having that value and that makes a lot of sense. If you’re not sure what your next five, six, seven years are, your overarching goal in life should be to value money so that you can feel like your future is secure and safe – much to what you’re saying. And I don’t argue that.
That doesn’t mean we shouldn’t also be thinking around the margins of whether within our discretionary income bucket – within the set of money that we spend in ways that enable us to enjoy our life – that we shouldn’t also be thinking about saving time. So that’s why I make the point, and my collaborators and I often argue that we need to be thinking about every time we open our wallet to make a purchase, a discretionary income purchase, is this money changing the way that I spend my time?
CURT NICKISCH: What’s one way that you have trained yourself to spend money on other things where maybe it was counterintuitive at first but really makes sense when you value time correctly?
ASHLEY WHILLANS: You know, going through grad school, you have no time and no money and you’re constantly trying to cut corners in every way that you can. And one thing that I did throughout all of graduate school was live really far away from my place of employment. I would spend hours on the bus every single day for five years because it was cheaper, I could live in a slightly bigger apartment with my partner, and I saved money that way.
You know, and so when I moved for my job, I had this intuition, this really strong sense that I should do the same thing. I should live in the most economical place even if it’s a little bit further away. And I really had to push against sort of every instinct that was saying, “But think about how much money you can save in rent!”
I’d just written this massive dissertation on the fact that we should value time over money, but we always get it wrong when making major and minor life decisions that I was like, “Okay Ashley. You can do it. You can pay a lot of money in rent and live really close to work so you can walk there. You’re going to be new. It’s going to be stressful. You have a million things to do.” And that was one thing that I did recently and I think it’s added a lot of happiness to my life and really reduced stress. I walk to the office, everything is walking distance to my house.
CURT NICKISCH: I feel like a lot of my behavior does come from how I first lived coming out of school from a time when I had more time than money and then just got used to doing everything myself. And there’s also the kind of the American self-reliance thing, just being able to take care of household chores, do things without having to hire somebody to do it.
ASHLEY WHILLANS: Yeah, I know, and I think this is part of the reason we see the effects that we see. So I have another line of research with Lora Park at the University of Buffalo and we look at how experiences in childhood around how much money you had and how much income inequality there was in a place where you grew up, shapes the way that adults think about their finances and make decisions, you know, 15, 20 years later.
And we do see that growing up in a more uncertain financial environment carries all the way through to adulthood. You know, it does involve a little bit of retraining. Again, I really want to return to this idea that it’s about taking small actions – not doing anything too drastic, but just sitting down and thinking about whether there’s anything you can outsource that you really don’t like, that stresses you out a lot, that you can afford.
And if there’s anything on a daily basis that the answer to that question is, “yes” – you should try it out. Try spending some discretionary income that way. You know, are there small ways I can be more efficient, that I can give up some of my money to have more time? Direct flights, grocery delivery to my house – not all the time, not outsource everything.
We show in our data that people who outsource too much experienced the lowest levels of happiness, in part probably because, again, they feel like their life must be so out of control if they can’t even do one load of laundry on the weekend. So I think you also raised an important point and we find this in our data: we want to seem self-sufficient.
One reason that we don’t ask for help enough, that we don’t outsource enough, even when we’re paying our hard earned money for someone else’s time is we want to feel like we can do it all. Especially in North American culture, we have this idea that we’re a failure if somehow we can’t have the perfect home life and be the most successful at work. I find in my studies that people feel really guilty about outsourcing even though they’re giving up money to have more time that they’ve earned.
CURT NICKISCH: There are social pressures to like – I don’t know, you can even feel extravagant if you’re having groceries delivered. I’ve definitely lived in neighborhoods where you would be looked at funny if a landscaping truck pulled up and did the work, you know, where it was expected that everybody, you know, mowed their own lawn. You might just feel guilty about doing something like that and also feel guilty about making other people do your chores for you. I just wonder if that’s like a big of what’s keeping people from doing this too and how people can get over that?
ASHLEY WHILLANS: Yeah. So we do have a paper showing exactly what you’re talking about. So, people feel guilty about burdening other people with their tasks. We also have some new data showing that customers are willing to pay more for services that are discreet. To this point that we feel pressured, we don’t want to look like we can’t maintain our own yard, heavens forbid! And so we do feel social pressure to not be outsourcing our tasks to others even though the convenience economy makes that very easy.
And I think in terms of ways to mitigate these feelings of guilt, again, thinking about what that time is going to buy you in terms of more meaningful interactions with your friends and family, more free time. You might not be able to change how many hours you work in a week, but you might be able to change how much of those hours you’re spending on yard work.
So focusing on what the time was going to get you versus what other people might think of you. And also focusing on the benefits of the job for the service provider. We found that consumers are more likely to make outsourcing purchases when they’re focusing on the benefits to the service provider, when they’re making these purchases from companies who provide a living wage and good benefits to the employees doing the tasks.
And I guess a little bit is on the service providers, or the companies rather, to make the services discreet if that’s what consumers want, given that there is a lot of external pressure to look like we’re keeping up with all of the demands of work and life.
CURT NICKISCH: Is a good way to approach this to come up with a value of your own time, like a dollar value per hour? I know this is something that, for instance, venture capitalists who are investing in startups, they tell the founder to do this. And they say, “Anything that you can have done for less than x dollars per hour, you should hire it out and don’t do it yourself.” Is that one way to do it – to try to equate time and money?
ASHLEY WHILLANS: I will get you part of the way there. So what that’s going to maybe help with is just getting you over this guilt that you might have around giving up money to have more free time – really putting a dollar value on your time and saying, “Well, if I don’t like it, it causes me stress and my time is worth more than what it costs me to outsource, then I should. I’m making a suboptimal decision.”
However, on the flip side of this, my research, research by Sanford DeVoe and Jeff Pfeffer has shown that just thinking about time as money makes people enjoy their leisure time less – be less social, less prosocial, it increases cortisol, a hormone associated with stress. And so we need to be a little careful – putting a dollar value on our time might make us maybe more likely to outsource, but it might also undermine our ability to enjoy the free time that we’ve just bought ourselves.
CURT NICKISCH: I can appreciate that too, and I hear this a lot from people who freelance, for instance, or let’s say you’re an Uber driver and you have a few free hours on Saturday. And if you go do something and you even spend money on something, you’re also calculating in your head well I’m not making this much money right now because I’m not working. And it could make it really hard to enjoy your free time because you’re often thinking about the opportunity cost of it all the time if you put a dollar value on it.
ASHLEY WHILLANS: So one thing that we’ve done in some experiments is to help people generate these opportunity costs. People are really bad at spontaneously generating opportunity costs. And this is especially true for time. So if we were not very good at thinking, “Well, if I spend three hours on this laundry, then that’s three hours that I could have spent doing something else.”
So one thing that we’ve done to take away this “Time Is Money” thinking, but also to help people recognize that every decision does have costs. We just simply remind people that if you are having a really busy weekend and you have four or five hours of chores to do at home, that means you’re going to have four or five less hours to spend in any other way that could promote meaning and happiness.
And actually just helping people remember that any tiniest decision means that it’s coming at a cost to being able to do something else seems to shift people towards making time-saving purchases, and to the conversation we were just having, is probably less likely to make people not enjoy their leisure time because they’re thinking their time is on the clock.
So just thinking about, “Well, if I do these really disliked tours with my time on a Saturday afternoon, what does this mean I’m going to miss out on?” And even just this question could help people shift their behavior more toward time, even if it comes at the expense of money.
CURT NICKISCH: There is an economic argument, sort of the comparative advantage argument that, you know, maybe instead of spending your time doing laundry or you know, getting stuff done on the weekend, you should moonlight and work a few extra hours and then have enough money to pay for that same amount of work to get done and hire somebody else to do it. And you feel like you, it hasn’t cost you – is that a good in between step or do you feel like that’s fallacy because you’re still spending the time and not enjoying it?
ASHLEY WHILLANS: I like the premise, although we know from a lot of behavioral economics research that people don’t act rationally. So, who’s to say that you’re not going to work a few more hours and then decide to work a few more hours and then because of guilt and cultural norms, you’re never going to outsource anyways?
And I think that’s actually what’s contributing to this trap in the first place, is we think, “Well, if I just make a little more money, then I can outsource to someone that can do these disliked tasks. But only if I just make a little bit more money.” But we see that even the world’s wealthiest – people with 3 million euros sitting in the bank – only 48 percent of them, or 50 percent, outsource their disliked tasks to others.
So I think the argument is solid, but I have yet to see people in my studies act in a way that’s sort of consistent with this rational economic model where, “Well, if I just make x amount of dollars and I work a little bit more hours, then the surplus that I make with this free time, I can use that to outsource my disliked tasks.”
CURT NICKISCH: What about the other end of the economic spectrum? You know, you’re talking about time poverty here, but what if you are cash-poor and you don’t have 3 million euros in the bank – does this concept apply to people at the opposite end of the socioeconomic spectrum?
ASHLEY WHILLANS: Yeah. So what we see in our data is that people who are the lowest socioeconomic status individuals in our studies – who deliberately make time saving purchases – they benefit the most from these purchases as compared to people in the middle and top end of the income distribution.
And what we think is going on there is that people who are materially constrained also tend to be time-poor. They might be working multiple jobs, they might be a single parent. They might have to commute really far away because the only place that they could live is somewhere that’s quite far away from where they work.
And so my collaborator, Colin West and I, are running a large-scale field experiment in Kenya, the largest slum, one of the largest slums in east Africa, and we’re buying women out of 10 hours, 15 hours of unpaid labor each week to really look at whether people – and women in particular who are often, especially in developing countries, burdened with most of these administrative costs, most of the burden of unpaid labor falls to women in this context.
We’re now interested in looking at whether time saving purchases, so in this case, buying women out of cooking and buying women out of laundry, which takes a long time there since they hand wash the laundry and then have to watch it dry because otherwise someone’s going to steal their laundry, so it takes a significant amount of time every week.
Whether we’re going to see much stronger effects for women living kind of at or below the poverty line, again, because people who are making the least amount of money in society often also tend to be the most time-constrained.
CURT NICKSICH: So let’s talk about some of the lowest-hanging fruit, or the best places for people to start and this is something that I think has come up in this conversation a lot because you’ve talked about laundry, you’ve talked about cooking, you’ve talked about household chores and you also talk about commuting. And are those kind of the best places to strike if you’re looking to purchase time?
ASHLEY WHILLANS: Yeah, I think they’re the easiest ways in. Things like paying someone to clean her house or outsourcing in terms of cooking – things that we have to do every day, commuting, yard work. So that’s sort of the first way in. I think importantly and maybe harder to do is thinking about where we can start trying to work less. Giving up some of our money to have more time in a more substantial way.
I have a new study that shows that college students who value money more than time, experience significant decreases in happiness over the next couple of years as compared to students who value time. Students who value time are more likely to make career choices that one, enabled them to have more free time, but also are more intrinsically motivated.
And so they experience greater happiness a couple of years out than students who are making career decisions based on money. And so the harder, maybe more meaningful thing to do for happiness, is to also think about how we can make major life decisions that enable us to have more free time.
CURT NICKISCH: So these are major life decisions like jobs, careers. But even things like which job should I take? The one that makes me drive further and has fewer vacation hours versus, you know, the one that may not be as demanding and is closer to where I live and gives me more vacation time? Those are big ones. Even if we’re already sort of stuck in our careers and can’t change that now. If I’m in finance, you know, it may be hard to switch just for happiness.
ASHLEY WHILLANS: Yeah. But maybe, you know, maybe you also think about whether you take on and promotion or not depending on how much free time you want to have. If you’re starting a family, you want to maybe be thinking about and having a conversation – not only amongst yourself but also with your partner. So you can think about time as a resource that you share with your partner if you live together and so how can you be maximizing the efficiency of tradeoffs not only for yourself but also for your partner, your family.
And so maybe it means one person is sacrificing more and one less. Maybe you both try to make some of these sacrifices together with really the end goal being having more time together as a family
CURT NICKISCH: And that means talking about it and deciding on it too.
ASHLEY WHILLANS: And we’re actually exactly doing some research on this right now – How do you even talk about time and money decisions with your partner? There’s shockingly very little data on this question and it’s so important. So we just finished a large study of working adult couples where we brought them into the lab and we ask them to talk about a financial goal or time-related goal to talk about these time, money tradeoffs.
And we’re now looking at which couples – we’re analyzing these data right now, but which couples are happier, how should you talk about these issues? So hopefully I can come back with some insights in a few months.
CURT NICKISCH: Lastly, I just – I wonder how much of this comes from the factory and clocking in and out and measuring things by hourly time. Even as salaried workers, we think about things that way. How much of this do you think is a holdover from the way people used to work?
ASHLEY WHILLANS: Yeah, I mean I think a lot of this “Time Is Money” thinking and this focus on productive outcomes does come from the Industrial Revolution, does come from when we used to – our inputs were directly quantified, you know, by time and by the amount that we produced.
But we know now that you know, our workplaces have changed so much. A good proportion of the workforce are knowledge workers with flexible hours that have to do creative work and there’s so much research suggesting that the most important, one of the most important things for creativity and productivity in these more qualitative domains, these domains that don’t have fixed outputs necessarily, or not very many of them, is time.
The more stressed we feel, the more we work, that actually comes at the detriment of our productivity and creativity in today’s labor market. So I think you’re absolutely right in the sense that a lot of this thinking is a carryover from the past, but I think we need to do a better job both as individuals and as organizations, as managers, to create a workplace and a thought process around work that reflects today’s demands.
CURT NICKISCH: Ashley, this has been really interesting and it’s a problem that I think many people have. So thanks so much for sharing your research insights into how we can do better at controlling the things that we can control, which is kind of how we spend our time and money to a large extent. So thank you.
ASHLEY WHILLANS: Thank you.
CURT NICKISCH: That’s Ashley Whillans. She’s an assistant professor at Harvard Business School and the author of the HBR article “Time for Happiness.” To learn more about time-money tradeoffs and to take a quiz on your spending behavior, go to HBR.org/time.
This episode was produced by Mary Dooe. We get technical help from Rob Eckhardt. Adam Buchholz is our audio product manager.
Thanks for listening to the HBR IdeaCast. I’m Curt Nickisch.